
AI has become an integral part of our lives, acting as both a copilot and an assistant. No matter what field we are in—finance, teaching, or software development—ChatGPT has made tasks easier than ever.
But have you ever wondered how ChatGPT was trained? Many people know that it was trained on vast amounts of data, but that’s only part of the story. In reality, ChatGPT’s training occurs in three key stages:
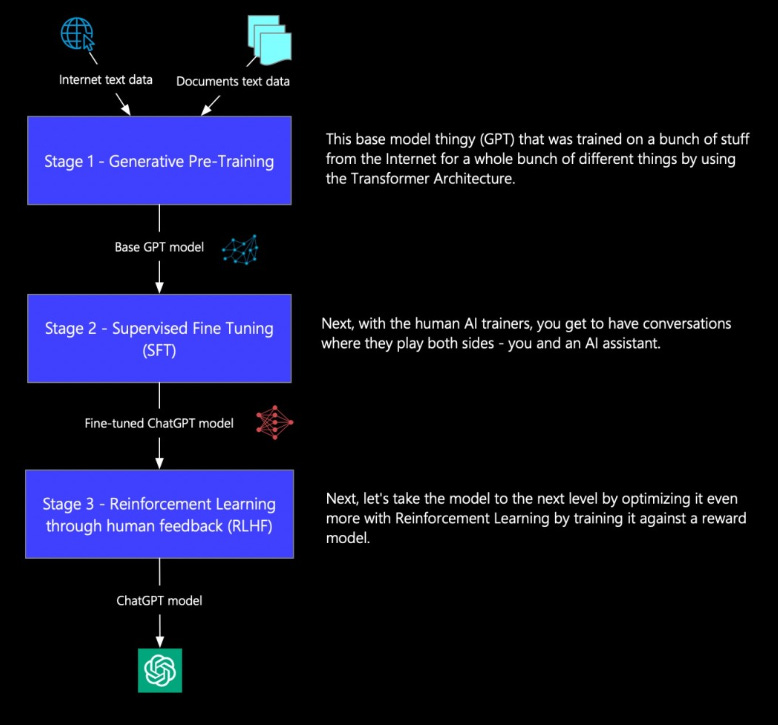
Stage 1: Generative Pre-Training
This stage might sound complex, but at its core, it involves training a Transformer model using massive amounts of internet text. Now, you might ask, What is a Transformer? For now, just think of it as the backbone of ChatGPT—we’ll explore it in more detail another time.
During this phase, the model learns from a variety of text sources, developing skills such as text summarization, language translation, and text completion. However, while this stage gives us a foundational GPT model, it doesn’t yet allow for natural, conversational interactions like we experience with ChatGPT today. That’s where the next stage comes in.
Stage 2: Supervised Fine-Tuning (SFT)
We engineers love to give fancy names to things—it makes us sound cool (well, we actually are cool 😎).
In this stage, the model is fine-tuned using real human conversations. AI trainers provide examples of interactions between humans (or humans acting like chatbots). This is where prompt engineering comes into play, helping the model understand how to respond more naturally.
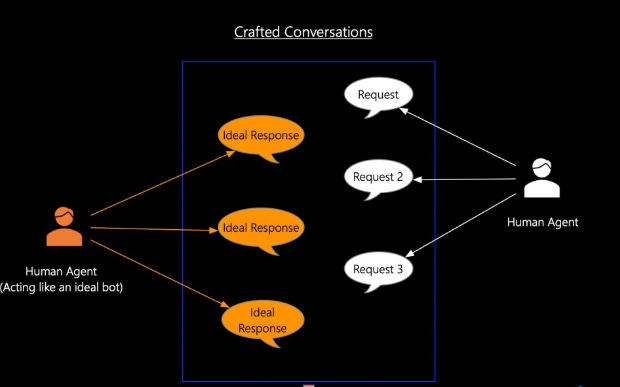
The entire chat history is then used to fine-tune the Base GPT model, resulting in an improved version known as the SFT ChatGPT model. This allows ChatGPT to engage in meaningful conversations. However, if a user asks something outside its training data, the model might generate awkward or inaccurate responses. That’s why we need Stage 3.
Stage 3: Reinforcement Learning from Human Feedback (RLHF)
Instead of providing just one response, the model now generates multiple possible responses for a given prompt. Human AI trainers then rank these responses based on preference.
Not just AI trainer we also sometimes multiple responses from ChatGPT.
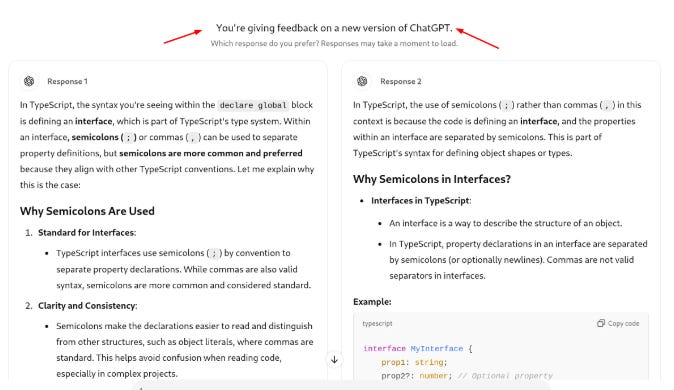
This feedback is used to refine ChatGPT’s behavior using Proximal Policy Optimization (PPO), an advanced reinforcement learning technique help an AI learn the best way to act in a given situation. It works by improving the AI's decision-making process step by step, without making sudden, extreme changes that could mess things up. PPO helps the model prioritize responses that align better with human expectations, improving both accuracy and user experience.
Conclusion
These three stages—Generative Pre-Training, Supervised Fine-Tuning, and Reinforcement Learning—are what make ChatGPT the powerful conversational AI it is today.